http://ru.wikipedia.org/wiki/%D0%90%D0%BB%D0%B3%D0%BE%D1%80%D0%B8%D1%82%D0%BC_%D1%88%D0%B8%D0%BD%D0%B3%D0%BB%D0%BE%D0%B2
"Канонизация текста приводит оригинальный текст к единой нормальной форме. Текст очищается от предлогов, союзов, знаков препинания, HTML тегов, и прочего ненужного «мусора», который не должен участвовать в сравнении. В большинстве случаев также предлагается удалять из текста прилагательные, так как они не несут смысловой нагрузки.
Также на этапе канонизации текста можно приводить существительные к именительному падежу, единственному числу, либо оставлять от них только корни."
:-)
"Шинглы (англ — чешуйки) — выделенные из статьи подпоследовательности слов. Необходимо из сравниваемых текстов выделить подпоследовательности слов, идущих друг за другом по 10 штук (длина шингла). Выборка происходит внахлест, а не встык. Таким образом, разбивая текст на подпоследовательности, мы получим набор шинглов в количестве равному количеству слов минус длина шингла плюс один (кол_во_слов — длина_шингла + 1)."
- а вот это "ещё немного" и будет похоже на "метрику" и "скалярное произведение".
Представьте себе одну простую штуку.
Сначала - "канонизируем текст".
Потом выделяем в нём "последовательности слов" по "словарю".
С учётом "перестановок" и "строгих словосочетаний".
Т.е. таки образом мы "покрываем предметную область".
Последовательностям мы приписываем "веса".
"Оставшимся" словам мы приписываем "другие веса". Меньшие.
При этом - "веса" приписываются по "ортам". Т.е. КАЖДОЕ слово или "словосочетание" это длина "орта".
Это понятно?
Т.е. для документа D1 получаем:
V1 = D11 * i1 + D12 * i2 + ... + D1N * iN
для документа D2 получаем:
V2 = D21 * i1 + D22 * i2 + ... + D2N * iN
Где DXY - длина орта, а iY - орт.
VX - вектор "описывающий" документ DX.
Понятно как скалярное произведение строить?
Понятно, что ортов может быть "МНОГО", но как раз "канонизация текста" и "выделение словосочетаний" как раз и направлены на "минимизацию числа ортов".
А ещё DXY можно нормализовать примерно так:
DXY' := (DXY div 10) * 10 + 1
Ну или точнее:
DXY' := (DXY div Max(DXY)) * Max(DXY) + 1
Или "скорее":
NXY := f(Max(DXY))
DXY' := (DXY div NXY) * NXY + 1
Где - f(Max(DXY)) - вероятностная оценка Max(DXY).
Главное что от "скалярного произведения" и "метрики" - вы никуда не уходим.
Есть "вектор" (документ) и есть "скалярное произведение векторов" (оценка похожести документов".
Это всё про "похожесть".
А про "полнотекстовый" поиск - "всё по-другому" - там банально "обратный индекс" и "слияние цепочек".
P.S. Исходный текст - http://programmingmindstream.blogspot.ru/2014/07/blog-post_5.html
Про метрики кстати:
http://ru.wikipedia.org/wiki/%D0%9C%D0%B5%D1%82%D1%80%D0%B8%D0%BA%D0%B0_(%D0%BC%D0%B0%D1%82%D0%B5%D0%BC%D0%B0%D1%82%D0%B8%D0%BA%D0%B0)
"Метрическое пространство есть пара , где
, где  — множество, а
— множество, а  — числовая функция, которая определена на декартовом произведении
— числовая функция, которая определена на декартовом произведении  , принимает значения в множестве вещественных чисел такая, что
, принимает значения в множестве вещественных чисел такая, что
-- при ВВЕДЕНИИ метрики надо ПОМНИТЬ эти АКСИОМЫ. Иначе - не работает.
Т.е. ВВЕДЁННАЯ метрика ДОЛЖНА удовлетворять аксиомам :-)
"Канонизация текста приводит оригинальный текст к единой нормальной форме. Текст очищается от предлогов, союзов, знаков препинания, HTML тегов, и прочего ненужного «мусора», который не должен участвовать в сравнении. В большинстве случаев также предлагается удалять из текста прилагательные, так как они не несут смысловой нагрузки.
Также на этапе канонизации текста можно приводить существительные к именительному падежу, единственному числу, либо оставлять от них только корни."
:-)
"Шинглы (англ — чешуйки) — выделенные из статьи подпоследовательности слов. Необходимо из сравниваемых текстов выделить подпоследовательности слов, идущих друг за другом по 10 штук (длина шингла). Выборка происходит внахлест, а не встык. Таким образом, разбивая текст на подпоследовательности, мы получим набор шинглов в количестве равному количеству слов минус длина шингла плюс один (кол_во_слов — длина_шингла + 1)."
- а вот это "ещё немного" и будет похоже на "метрику" и "скалярное произведение".
Представьте себе одну простую штуку.
Сначала - "канонизируем текст".
Потом выделяем в нём "последовательности слов" по "словарю".
С учётом "перестановок" и "строгих словосочетаний".
Т.е. таки образом мы "покрываем предметную область".
Последовательностям мы приписываем "веса".
"Оставшимся" словам мы приписываем "другие веса". Меньшие.
При этом - "веса" приписываются по "ортам". Т.е. КАЖДОЕ слово или "словосочетание" это длина "орта".
Это понятно?
Т.е. для документа D1 получаем:
V1 = D11 * i1 + D12 * i2 + ... + D1N * iN
для документа D2 получаем:
V2 = D21 * i1 + D22 * i2 + ... + D2N * iN
Где DXY - длина орта, а iY - орт.
VX - вектор "описывающий" документ DX.
Понятно как скалярное произведение строить?
Понятно, что ортов может быть "МНОГО", но как раз "канонизация текста" и "выделение словосочетаний" как раз и направлены на "минимизацию числа ортов".
А ещё DXY можно нормализовать примерно так:
DXY' := (DXY div 10) * 10 + 1
Ну или точнее:
DXY' := (DXY div Max(DXY)) * Max(DXY) + 1
Или "скорее":
NXY := f(Max(DXY))
DXY' := (DXY div NXY) * NXY + 1
Где - f(Max(DXY)) - вероятностная оценка Max(DXY).
Главное что от "скалярного произведения" и "метрики" - вы никуда не уходим.
Есть "вектор" (документ) и есть "скалярное произведение векторов" (оценка похожести документов".
Это всё про "похожесть".
А про "полнотекстовый" поиск - "всё по-другому" - там банально "обратный индекс" и "слияние цепочек".
P.S. Исходный текст - http://programmingmindstream.blogspot.ru/2014/07/blog-post_5.html
Про метрики кстати:
http://ru.wikipedia.org/wiki/%D0%9C%D0%B5%D1%82%D1%80%D0%B8%D0%BA%D0%B0_(%D0%BC%D0%B0%D1%82%D0%B5%D0%BC%D0%B0%D1%82%D0%B8%D0%BA%D0%B0)
"Метрическое пространство есть пара
, где — множество, а — числовая функция, которая определена на декартовом произведении , принимает значения в множестве вещественных чисел такая, что (аксиома тождества).
(аксиома тождества). (аксиома симметрии).
(аксиома симметрии).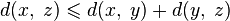 (аксиома треугольника или неравенство треугольника).
(аксиома треугольника или неравенство треугольника).
При этом
- множество называется подлежащим множеством метрического пространства.
- элементы множества называются точками метрического пространства.
- функция называется метрикой.
-- при ВВЕДЕНИИ метрики надо ПОМНИТЬ эти АКСИОМЫ. Иначе - не работает.
Т.е. ВВЕДЁННАЯ метрика ДОЛЖНА удовлетворять аксиомам :-)
«А про "полнотекстовый" поиск - "всё по-другому" - там банально "обратный индекс" и "слияние цепочек".»
ОтветитьУдалить-- Отнюдь... Очень много общего. И нормализация там есть, и морфология и даже учёт словосочетаний (вроде вашего словаря). Но да, инверированный список присутствует, без него - никак.
Вот - позабавило... И почему-то вспомнилось из Онегина:
«...Ученый малый, но педант.
Имел он счастливый талант
Без принужденья в разговоре
Коснуться до всего слегка...»
-- Не поспоришь: коснулся если не до всего, то до многого - уж точно. Это - талант...
Я это к тому, что в полнотекстовом поиске не так всё просто, Александр...
"Я это к тому, что в полнотекстовом поиске не так всё просто, Александр..."
Удалить-- я знаю :-) Я его писал...
Ну, я не знаю, что Вы писали, но результаты
Удалить«там банально "обратный индекс" и "слияние цепочек"»
-- IMHO вполне описаны на стр. 14 из 35 по приведённой ссылке...
"IMHO вполне описаны на стр. 14 из 35 по приведённой ссылке"
Удалить-- Вы сами сказали "в полнотекстовом поиске не так всё просто" :-)
Именно так.
УдалитьЕще интересует следующая вещь.
ОтветитьУдалитьКакие юридические документы считать "похожими"? Например, документ утверждает состав комиссии. Там есть всего одна ключевая фраза "утвердить состав комиссии", а остальные 99% текста состоят из перечисления членов комиссии с из должностями. Так вот, в других документах эти ФИО, а также должности встречаются очень часто. И получается, что наш алгоритм вместо иголки (ключевой фразы "утвердить состав комиссии") выдаст гору сена в виде документов, где встречаются эти же самые фамилии или должности.
Или есть документ об изъятии земельного участка. Опять же, во всем тексте нам важна только одна фраза "изъять земельный участок", а остальные слова - например, топонимы, которые также будут в других документах встречаться, не являются существенными для сравнения. А алгоритм будет просто находить "похожие" документы, где перечислены эти же географические названия, хотя они упоминаются в куче документов, не относящихся к нужной нам теме.
По этой причине, как мне кажется, для получения качественных результатов необходимо, все-таки, составлять словарь тематик и для каждой тематики задавать характерные фразы с весами. Т.е. если такие фразы встречаются, то прибавлять вес документа к этой тематике.
Ну, вы поняли. Я говорю о том, что в юридических документах "похожесть" документов определяется не количественным соотношением аналогичных слов (словесный мусор везде повторяется один и тот же), а некими характерными фразами, который могут составлять менее 1% от тела документа. То есть "в лоб", математикой, эту задачу так просто не решить. Ну, я думаю, что Александр сам прекрасно это знает.
Дмитрий, по-моему - вы ответили САМИ на свой вопрос. Если "ФИО" - "мусор", то наверное оно "мусор" - ВСЕГДА. И значит его его надо выкидывать при КАНОНИЗАЦИИ.
Удалить"Ну, я думаю, что Александр сам прекрасно это знает."
Знает.
Кстати наш поиск похожих вас не удовлетворяет?
"По этой причине, как мне кажется, для получения качественных результатов необходимо, все-таки, составлять словарь тематик и для каждой тематики задавать характерные фразы с весами. Т.е. если такие фразы встречаются, то прибавлять вес документа к этой тематике. "
О чём по-моему и написано ВЫШЕ, в посте.
Нет?
Ну и потом - "в НАШЕМ СЛУЧАЕ" есть ДРУГИЕ атрибуты документов - ТИП, ИСТОЧНИК, КЛАССЫ, ТЕМЫ. Понимаете?
УдалитьЭтот комментарий был удален автором.
ОтветитьУдалитьВсе верно, я по специфике работы, в основном, и пользуюсь поиском по реквизитам + БП. Всё устраивает.
ОтветитьУдалитьАлександр, хотел еще одну вещь предложить. Не знаю, используете или нет.
По крайней мере, в региональных документах степень похожести можно очень быстро определить с помощью сравнения преамбул документов. Как известно, в преамбуле чиновники пишут "вступление" - в связи с чем они приняли данный нормативный акт. А потом - в последующих аналогичных документах - они просто копируют готовую преамбулу. Для разных видов нормативных актов эти преамбулы разные - упоминаются разные федеральные и региональные НПА. А в аналогичных документах - преамбулы очень характерные и практически полностью повторяются.
Понятно, что только по преамбулам сравнивать нельзя, т.к. во многих документах их нет, но можно использовать результат сравнение преамбул для повышения/понижения релевантности. Т.е. это наиболее важная часть после сравнение названий документов.
Дмитрий, я к тому, что "похожесть" определяется не только "на основе текста". Но и на основе других данных.
УдалитьА БП - как раз работает по тексту. Правда тоже "интеллектуально". Например не только с учётом морфологии, но и с учётом "канонизации".
Что касается "преамбулы" - это "предложение" или "попытка поделиться"? Преамбулу в БП кстати вводить не пробовали? Это - вопрос :-) Я - НЕ ПРОБОВАЛ.
Да просто "идея на вынос" ) Я ж не знаю, как у вас там все устроено в деталях. Можете попробовать - а вдруг хороший результат будет с минимальными затратами? Насчет БП - нет, не пробовал. Мне кажется, целая преабула просто не влезет в БП - обрежется по длине.
ОтветитьУдалитьМожно еще сильней упростить: в преамбуле идут ссылки на НПА, согласно которым утвержден настоящий документ. Более того, ссылки могут идти на конкретные статьи федеральных законов или на определенные положения. Так вот, если из преамбулы идет 4 - 5 ссылок на определенные федеральные и региональные НПА, то большая доля вероятности, что в аналогичном документе будут аналогичный набор ссылк. То есть, грубо говоря, можно даже не анализировать текст, а сравнить список ссылок, идущих в начале документа. Конечно, это все нужно пробовать и тестировать, там куча нюансов будет.